


Bản dịch Tác nhân AI từ sách trắng của Google phát hành đầu 2025, làm rõ kiến trúc, ứng dụng, và hướng tiếp cận triển khai Tác nhân AI.
Lời người dịch
Tôi may mắn được biết đến Sách trắng (Whitepaper) về Tác nhân (AI Agent) do nhóm tác giả - gồm những lãnh đạo cấp cao của Google về sản phẩm nói chung và lĩnh vực Trí tuệ nhân tạo (AI) nói riêng.
Từ năm 2016, tôi đã tìm hiểu về Trí tuệ nhân tạo (AI) và Tác nhân (Agent) qua nhiều kênh khác nhau – đọc bài viết, nghe podcast và xem video. Tuy nhiên, dự án dịch thuật này là lần đầu tiên tôi dành thời gian để tập trung hoàn toàn vào việc đọc và phân tích một sách trắng chuyên sâu về Tác nhân. Đây là một cơ hội quý báu để tôi củng cố và hệ thống hóa những kiến thức và quan sát rời rạc mà tôi đã tích lũy được về lĩnh vực rất mới mẻ này.
Trong quá trình đọc bản gốc bằng tiếng anh và dịch tài liệu này, tôi nhận ra rằng một số dự án phát triển của mình đã có cấu trúc tốt, trong khi một số khác thì chưa. Whitepaper này thực sự có tác động lớn đến tôi, với vai trò một nhà phát triển đã xây dựng các giải pháp ứng dụng AI bằng AppSheet, Apps Script, NodeJS, Vertex AI, Google APIs và các thành phần khác trong hệ sinh thái Google Workspace. Nhờ Whitepaper này, tôi có cơ hội nhìn nhận lại và học hỏi để cải thiện cấu trúc cho các dự án tương lai.
Với vai trò là Chuyên gia Phát triển của Google (GDE), tôi đã có những tương tác, quan sát và đưa ra các dự đoán của riêng mình về cách Google xây dựng cấu trúc sản phẩm và triển khai Tác nhân vào nhiều phạm vi công việc của họ. Sau khi củng cố và hệ thống hóa ki�ến thức về Tác nhân thông qua whitepaper này, tôi nhận thấy rằng tài liệu này không chỉ hé lộ kiến trúc cơ bản của nhiều sản phẩm Google mà còn cho thấy dự đoán của tôi là có căn cứ, đồng thời, nội dung cuốn sách là sự khẳng định vì sao Google đã và có thể tiếp tục triển khai và ứng dụng Tác nhân ở cấp độ rộng lớn, bởi họ đã làm mọi thứ trên một nền tảng kiến trúc rất chặt chẽ, với chiến lược tiếp cận rõ ràng, đặc biệt là nhận định của họ về vai trò và tiềm năng của mạng tác nhân chuyên gia.
Tôi tin rằng, sau khi nghiền ngẫm bản dịch này, quý bạn đọc sẽ:
- Hiểu sâu sắc về Tác nhân AI: Nắm vững các khái niệm cốt lõi, thành phần cấu tạo và nguyên lý hoạt động của Tác nhân AI, từ đó có cái nhìn tổng quan và hệ thống về lĩnh vực này.
- Tiếp cận kiến thức chuyên sâu từ Google: Tiếp cận được những kiến thức chuyên môn và góc nhìn chiến lược của Google về kiến trúc Tác nhân AI, một trong những công ty hàng đầu thế giới về AI.
- Nắm bắt các yếu tố then chốt để xây dựng ứng dụng Tác nhân AI: Hiểu rõ về Lớp điều hành (Orchestration Layer), các loại Công cụ (Extensions, Functions, Data Stores) và các phương pháp học tập mục tiêu, từ đó có nền tảng vững chắc để tự mình xây dựng các ứng dụng Tác nhân AI hiệu quả.
- Tìm thấy nguồn cảm hứng và ý tưởng mới: Khám phá tiềm năng ứng dụng rộng lớn của Tác nhân AI trong thực tế, từ đó khơi gợi những ý tưởng sáng tạo và ứng dụng mới cho công việc và dự án của bản thân.
- Nâng cao vốn từ vựng kỹ thuật: Làm quen và nắm vững các thuật ngữ chuyên ngành quan trọng trong lĩnh vực Tác nhân AI bằng tiếng Việt, giúp bạn tự tin hơn trong việc đọc hiểu và nghiên cứu các tài liệu chuyên sâu khác.
Đây là lần đầu tiên tôi dịch một tài liệu kỹ thuật phức tạp về hệ thống, kiến trúc và các khái niệm chuyên sâu như vậy. Trong quá trình dịch, cá nhân tôi cho rằng Tiếng Việt chưa có sẵn từ ngữ tương đương cho một số thuật ngữ kỹ thuật trong tài liệu này, thêm nữa, dù đã quan sát và làm về AI nhưng có nhiều chỗ tôi thấy vẫn chưa thông suốt, do đó, tôi khá tự tin khi cho rằng, bản dịch của tôi sẽ có các thiếu sót cần chỉnh sửa. Rất mong nhận được sự phản hồi và góp ý chân thành từ mọi người để bản dịch này được hoàn thiện và chính xác hơn. Mọi góp ý xin gửi về: hi@timkhachhang.net.
Bản dịch này hướng đến nhiều đối tượng độc giả khác nhau, nhưng cá nhân tôi nghĩ sẽ phù hợp nhất với các nhóm dưới đây:
Nhà phát triển Việt Nam (Developer) quan tâm đến công nghệ AI và Tác nhân, những người muốn tìm hiểu sâu hơn về kiến trúc và nguyên lý hoạt động của Tác nhân AI, đặc biệt trong hệ sinh thái Google.
Chuyên gia IT và những người đam mê công nghệ muốn nâng cao kiến thức về AI và các hệ thống thông minh hiện đại.
Sinh viên và nhà nghiên cứu trong lĩnh vực Khoa học Máy tính và AI, xem đây là tài liệu tham khảo giá trị cho học tập và nghiên cứu.
Các nhà lãnh đạo doanh nghiệp và quản lý sản phẩm trong ngành công nghệ, những người đang tìm hiểu về ứng dụng AI và muốn nắm bắt các khía cạnh kỹ thuật để đưa ra quyết định chiến lược.
Bất kỳ ai quan tâm đến chiến lược AI của Google và tầm nhìn sản phẩm của họ trong lĩnh vực AI.
Xin trân trọng mời quý bạn đọc bản dịch: Tác Nhân (Agents)
Khái niệm về tác nhân được gợi mở từ sự kết hợp giữa khả năng lý luận, logic, và khả năng truy cập thông tin bên ngoài của một mô hình AI tạo sinh.
Giới thiệu
Con người có khả năng đặc biệt trong việc nhận biết các mẫu hình phức tạp, dù chúng có lộn xộn đến đâu. Tuy nhiên, để bổ sung vào các kiến thức đã có trước khi đưa ra kết luận cuối cùng, con người thường cần đến sự hỗ trợ của các công cụ, ví dụ như sách, công cụ tìm kiếm Google, hay máy tính cầm tay.
Tương tự như con người, các mô hình AI tạo sinh cũng có thể được huấn luyện để sử dụng các công cụ. Nhờ đó, chúng có thể truy cập thông tin theo thời gian thực hoặc đề xuất các hành động diễn ra hàng ngày. Ví dụ, một mô hình AI tạo sinh có thể dùng một công cụ tìm dữ liệu, để tự động lấy ra thông tin chi tiết về lịch sử mua sắm của khách hàng, sau đó, nó đưa ra gợi ý mua sắm riêng cho từng người.
Sau khi dựa vào các câu hỏi mà bạn đặt ra, mô hình AI tạo sinh cũng có thể thay bạn gửi email trả lời các đồng nghiệp, hoặc hoàn tất thực hiện các giao dịch tài chính, mua bán.
Để làm được điều đó, mô hình AI tạo sinh không chỉ cần quyền sử dụng các công cụ bên ngoài, mà còn phải tự mình lên kế hoạch và thực hiện mọi việc một cách chủ động. Sự kết hợp giữa khả năng suy luận, tư duy logic, và khả năng tiếp cận thông tin bên ngoài – tất cả được tích hợp trong một mô hình AI tạo sinh – chính là điều đã tạo nên khái niệm về tác nhân. Tác nhân, ở đây, có thể hiểu là một chương trình máy tính có năng lực vượt trội hơn hẳn so với các mô hình AI tạo sinh thông thường. Trong tài liệu này, chúng tôi s��ẽ đi sâu vào khám phá khái niệm tác nhân cùng những khía cạnh liên quan khác một cách chi tiết.
Tác nhân là gì?
Về bản chất, tác nhân AI tạo sinh có thể được định nghĩa là một ứng dụng, nỗ lực đạt được một hoặc nhiều mục tiêu, bằng cách quan sát và tương tác với thế giới xung quanh thông qua sử dụng những công cụ có sẵn. Tác nhân trong tiếng anh gọi là Agent.
Tác nhân có tính tự chủ và có thể hoạt động độc lập mà không cần sự can thiệp của con người, đặc biệt khi chúng được cung cấp các mục tiêu hoặc nhiệm vụ rõ ràng cần phải hoàn thành. Tác nhân cũng có thể chủ động trong cách tiếp cận để đạt được mục tiêu của mình. Ngay cả khi không có chỉ thị hoặc yêu cầu cụ thể nào từ con người, tác nhân vẫn có thể tự suy luận về những việc tiếp theo cần làm để cuối cùng đạt được mục tiêu đã đặt ra. Mặc dù khái niệm về tác nhân trong AI rất rộng, nhưng trong tài liệu này, chúng tôi sẽ tập trung đề cập đến các loại tác nhân cụ thể mà mô hình AI tạo sinh có khả năng xây dựng tính đến thời điểm tài liệu này được phát hành tháng 12 năm 2024.
Để hiểu rõ hơn về cơ chế hoạt động bên trong của một tác nhân, trước tiên chúng ta hãy cùng tìm hiểu về các thành phần cơ bản cấu thành hành vi, hành động và khả năng ra quyết định của tác nhân. Sự kết hợp của các thành phần này có thể được mô tả như một kiến trúc nhận thức, và có rất nhiều kiến trúc nhận thức khác nhau được tạo ra bằng cách kết hợp và sắp xếp các thành phần này theo nhiều cách khác nhau. Tập trung vào các chức năng cốt lõi, một kiến trúc nhận thức của tác nhân thường bao gồm ba thành phần thiết yếu, như được minh họa trong Hình 1.
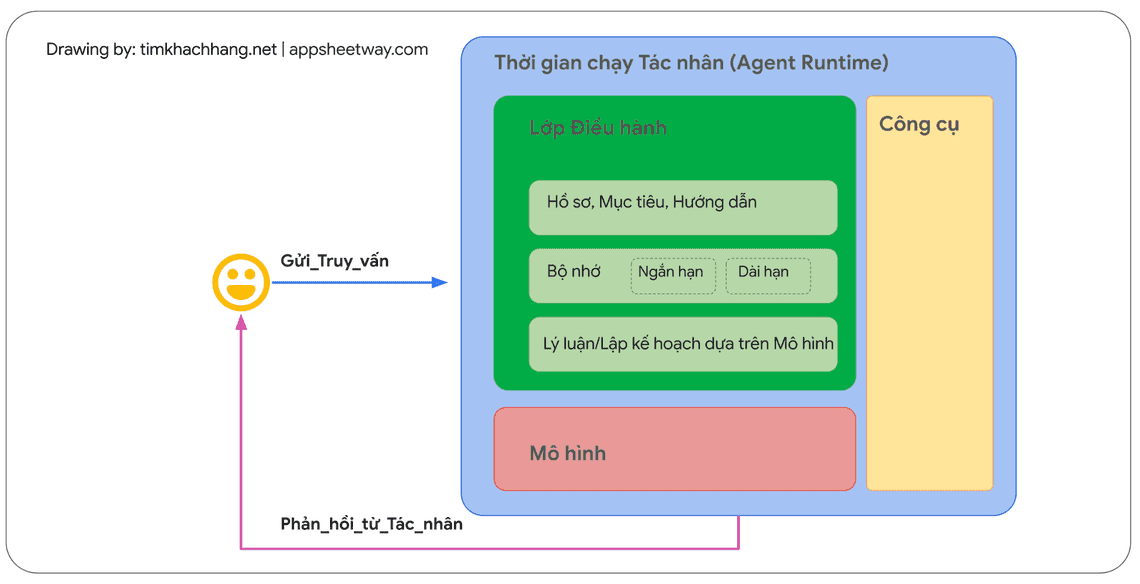
Mô hình
Trong phạm vi trao đổi về tác nhân, mô hình nói đến chính là mô hình ngôn ngữ (LM), được sử dụng như trung tâm đưa ra quyết định cho các quy trình hoạt động của tác nhân.
Tác nhân có thể sử dụng một hoặc nhiều mô hình ngôn ngữ với kích thước lớn nhỏ bất kỳ, miễn sao chúng có khả năng tuân theo các khuôn khổ cơ bản về lý luận và logic dựa trên chỉ dẫn, ví dụ như ReAct (Lý luận - Hành động), Chain-of-Thought (Chuỗi Suy luận), hoặc Tree-of-Thoughts (Cây Tư duy).
Các mô hình có thể là đa chức năng, đa phương thức hoặc được tinh chỉnh tùy theo nhu cầu cụ thể về kiến trúc tác nhân của bạn.
Nên lựa chọn mô hình ngôn ngữ như thế nào?
Để đạt được kết quả tốt nhất trong môi trường sản xuất, bạn nên tận dụng một mô hình phù hợp nhất với ứng dụng cuối cùng mà bạn mong muốn. Lý tưởng nhất là lựa chọn mô hình đã được huấn luyện trên các đặc điểm dữ liệu liên quan đến các công cụ bạn dự định sử dụng trong kiến trúc nhận thức.
Trong thực tế vận hành, thường có các bước thiết lập cấu hình cụ thể cho tác nhân, ví dụ như lựa chọn về công cụ, cấu hình điều hành/lý luận. Tuy nhiên, các mô hình ngôn ngữ thông thường lại không được huấn luyện từ trước với các thiết lập cấu hình cụ thể của từng tác nhân. Trong trường hợp này, bạn cần tinh chỉnh mô hình để nó phù hợp với các nhiệm vụ hay công việc mà tác nhân sẽ thực hiện. Bạn tinh chỉnh bằng cách cung cấp cho mô hình các ví dụ thể hiện năng lực của tác nhân, bao gồm các trường hợp tác nhân sử dụng công cụ cụ thể như thế nào, hoặc các bước tiến hành lý luận trong các ngữ cảnh khác nhau.
Công cụ
Các mô hình nền tảng, dù đã đạt được những thành tựu ấn tượng trong việc tạo ra văn bản, hình ảnh, video, những vẫn gặp hạn chế về khả năng tương tác với thế giới thực bên ngoài. Công cụ chính là cầu nối giúp khắc phục hạn chế này.
Thông qua công cụ, các tác nhân được trao quyền để tương tác với dữ liệu và dịch vụ bên ngoài, từ đó mở rộng phạm vi hành động rộng lớn hơn cho tác nhân, giúp tác nhân vượt xa khả năng thông thường của các mô hình nền tảng.
Công cụ có thể đa dạng về hình thức và mức độ phức tạp, nhưng thường tuân theo các phương thức kết nối/tích hợp API phổ biến như GET, POST, PATCH và DELETE.
Ví dụ, thông qua công cụ, tác nhân có thể cập nhật thông tin khách hàng vào trong cơ sở dữ liệu thực tế của doanh nghiệp, hoặc tác nhân đưa ra gợi ý phù hợp nhất cho người dùng thông qua việc kết nối với công cụ thu thập dữ liệu thời tiết. Nhờ công cụ, tác nhân có thể tiếp cận và xử lý thông tin trong thế giới thực. Điều này cho phép tác nhân được triển khai trong các hệ thống chuyên biệt hơn, điển hình là kỹ thuật tạo sinh tăng cường truy xuất thông tin (RAG), một công nghệ giúp mở rộng khả năng của tác nhân lên một tầm cao mới, vượt xa năng lực vốn có của mô hình nền tảng.
Chúng ta sẽ thảo luận chi tiết hơn về công cụ ở phần sau. Điều quan trọng nhất cần lưu ý: Công cụ đóng vai trò cầu nối giữa năng lực nội tại của tác nhân và thế giới bên ngoài, mở ra vô vàn khả năng mới.
Lớp điều hành
Lớp điều hành mô tả một vòng lặp. Lớp điều hành chi phối cách tác nhân tiếp nhận thông tin, thực hiện các suy luận nội tại, và sử dụng kết quả suy luận đó để định hướng hành động hoặc quyết định tiếp theo.
Nhìn chung, vòng lặp này sẽ tiếp tục cho đến khi tác nhân đạt được mục tiêu hoặc dừng lại tại một thời điểm nhất định.
Lớp điều hành có độ phức tạp khác nhau, tùy thuộc vào từng tác nhân và các nhiệm vụ mà tác nhân đó được giao để thực hiện.
Một số vòng lặp có thể chỉ là các phép tính đơn giản với vài quy tắc để ra quyết định, trong khi những vòng lặp phức tạp khác, có thể chứa logic dạng chuỗi, kết hợp thêm các thuật toán học máy, hoặc triển khai các kỹ thuật lý luận xác suất khác. Chúng ta sẽ thảo luận chi tiết hơn về việc triển khai lớp điều hành của tác nhân trong phần kiến trúc nhận thức.
So sánh Tác nhân và Mô hình
Bảng dưới so sánh rõ hơn về sự khác biệt giữa tác nhân và mô hình:
| Mô hình (Model) | Tác nhân (Agent) |
| Kiến thức bị giới hạn trong dữ liệu huấn luyện từ trước. | Kiến thức được mở rộng nhờ kết nối với các hệ thống bên ngoài thông qua các công cụ. |
| Suy luận / dự đoán đơn lẻ: chỉ dựa trên truy vấn đơn lẻ của người dùng, thông thường không có tính năng quản lý lịch sử trò chuyện (ngoại trừ trường hợp các mô hình có các thiết kế riêng) | Suy luận / dự đoán nhiều lượt: Thông qua quản lý lịch sử trò chuyện, tác nhân có thể suy luận/dự đoán nhiều lượt dựa trên tất cả truy vấn của người dùng và các quyết định được đưa ra ở lớp điều hành. Trong ngữ cảnh này, lượt tương tác được hiểu là một tương tác giữa hệ thống tương tác và tác nhân (ví dụ: 1 sự kiện/truy vấn đến và 1 phản hồi của tác nhân) |
| Công cụ: không được triển khai ngay từ ban đầu. | Công cụ: Được triển khai ngay từ trong kiến trúc của tác nhân |
| Lớp logic: Không triển khai lớp logic nào từ ban đầu. Người dùng đưa ra yêu cầu dưới dạng câu hỏi đơn giản hoặc sử dụng các khuôn khổ lý luận để mô tả các yêu cầu phức tạp hơn, nhằm dẫn dắt mô hình trong quá trình dự đoán. | Lớp logic: Kiến trúc nhận thức gốc được triển khai bằng cách sử dụng các khuôn khổ lý luận như Chain-of-Thought (CoT), ReAct hoặc các khuôn khổ tác nhân được xây dựng sẵn như LangChain. |
Kiến trúc nhận thức: Cách tác nhân vận hành
Hãy tưởng tượng bạn là một đầu bếp trong một nhà hàng năm sao bận rộn. Mục tiêu của bạn lúc này là tạo ra những món ăn ngon cho các khách hàng. Để đạt mục tiêu, bạn phải thực hiện một chu trình gồm lập kế hoạch, thực hiện và điều chỉnh liên tục.
Bạn thu thập thông tin, ví dụ như món ăn khách hàng gọi và những nguyên liệu có trong tủ đựng thức ăn và tủ lạnh.
Bạn thực hiện một số suy luận nội tại về những món ăn và hương vị mà bạn có thể tạo ra dựa trên thông tin vừa thu thập được.
Bạn hành động để tạo ra món ăn: chặt rau củ, trộn gia vị, áp chảo thịt.
Tại mỗi giai đoạn trong quy trình chế biến, bạn sẽ điều chỉnh khi cần thiết, tinh chỉnh kế hoạch khi nguyên liệu cạn dần hoặc khi nhận được phản hồi (tốt/xấu) từ khách hàng, và sử dụng những kết quả trước đó để xác định kế hoạch hành động tiếp theo. Chu trình tiếp nhận thông tin, lập kế hoạch, thực hiện và điều chỉnh này mô tả một kiến trúc nhận thức độc đáo mà bạn, trong trường hợp này là đầu bếp của nhà hàng, sử dụng để đạt được mục tiêu đặt ra.
Tương tự như bạn - người đóng vai đầu bếp trong ví dụ nêu trên, tác nhân sử dụng kiến trúc nhận thức để đạt được mục tiêu cuối cùng bằng cách xử lý thông tin lặp đi lặp lại, đưa ra quyết định sáng suốt, và tinh chỉnh các hành động tiếp theo dựa trên kết quả đầu ra trước đó.
Yếu tố cốt lõi trong kiến trúc nhận thức của tác nhân chính là lớp điều hành, chịu trách nhiệm duy trì bộ nhớ, trạng thái, khả năng lý luận và lập kế hoạch. Lớp điều hành tận dụng các kỹ thuật ra lệnh (prompt) đang phát triển nhanh chóng và các khuôn khổ lý luận liên quan, để hướng dẫn quá trình lý luận và lập kế hoạch, từ đó cho phép tác nhân tương tác hiệu quả hơn với môi trường thực tế và hoàn thành nhiệm vụ.
Các nghiên cứu trong lĩnh vực kỹ thuật ra lệnh (prompt) cho máy và lập kế hoạch thực thi các nhiệm vụ cho các mô hình ngôn ngữ đang phát triển nhanh chóng, mang lại nhiều phương pháp đầy hứa hẹn. Mặc dù không thể liệt kê hết, nhưng dưới đây là ba khuôn khổ và kỹ thuật lý luận phổ biến nhất tại thời điểm tài liệu này được phát hành:
ReAct (Suy luận - Hành động): Khuôn khổ kỹ thuật ra lệnh (prompt) cung cấp quy trình tư duy chiến lược cho mô hình ngôn ngữ, để lý luận và hành động dựa trên truy vấn (câu lệnh) của người dùng, có kèm theo hoặc không kèm theo các ví dụ tham khảo. Kỹ thuật ra lệnh ReAct đã được chứng minh là vượt trội hơn so với nhiều mô hình cơ sở tiên tiến (baseline SOTA) và cải thiện khả năng tương tác và độ tin cậy của mô hình ngôn ngữ lớn (LLM) đối với con người.
Chain-of-Thought (CoT): Khuôn khổ kỹ thuật ra lệnh (prompt) cho phép mô hình có khả năng lý luận thông qua các bước trung gian. Có nhiều kỹ thuật nhánh con của CoT, bao gồm tính nhất quán tự thân, active-prompt, và CoT đa phương thức, mỗi kỹ thu�ật có điểm mạnh và điểm yếu riêng tùy thuộc vào ứng dụng cụ thể.
Tree-of-thoughts (ToT): Khuôn khổ kỹ thuật ra lệnh (prompt) phù hợp với các nhiệm vụ khám phá hoặc lập kế hoạch chiến lược. ToT tổng quát hóa từ kỹ thuật ra lệnh CoT và cho phép mô hình khám phá nhiều chuỗi tư duy khác nhau, đóng vai trò là các bước trung gian để giải quyết các bài toán tổng quát với mô hình ngôn ngữ.
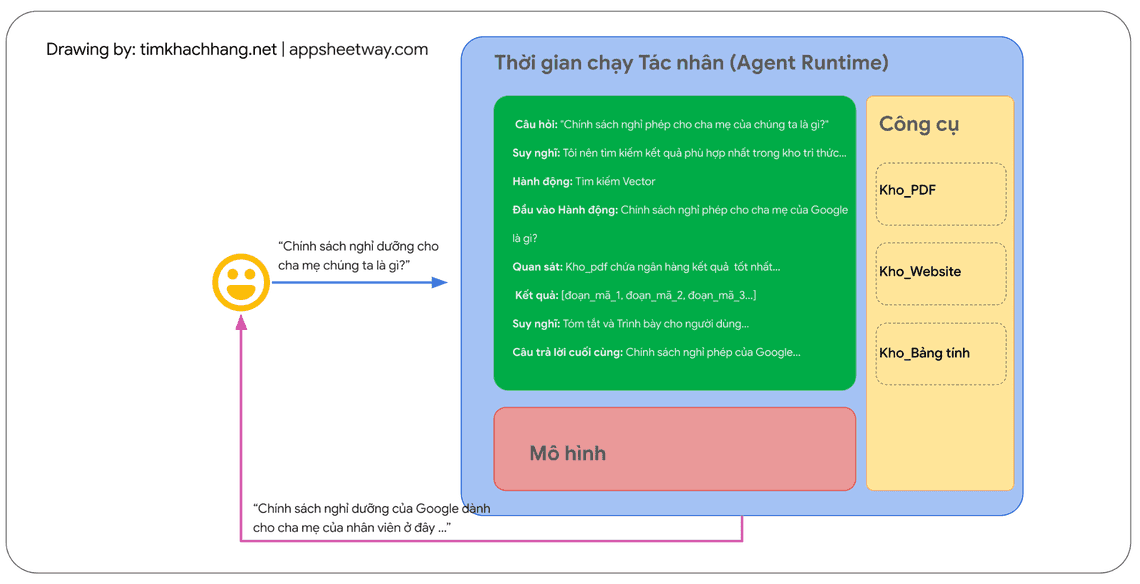
Tác nhân có thể sử dụng các kỹ thuật trong các khuôn khổ lý luận nêu trên, hoặc nhiều kỹ thuật khác, để chọn ra hành động tiếp theo tốt nhất cho yêu cầu cụ thể của người dùng. Ví dụ, hãy xem xét một tác nhân được lập trình để sử dụng khuôn khổ ReAct nhằm lựa chọn hành động và công cụ phù hợp cho truy vấn của người dùng. Trình tự các sự kiện có thể diễn ra như sau:
1. Người dùng gửi truy vấn đến tác nhân
2. Tác nhân bắt đầu chuỗi ReAct (Suy luận - Hành động)
3. Tác nhân cung cấp một lệnh (prompt) cho mô hình, yêu cầu mô hình tạo ra một trong các bước ReAct tiếp theo và kết quả tương ứng:
Câu hỏi: Là câu hỏi đầu vào từ truy vấn của người dùng, được cung cấp cùng với prompt
Suy nghĩ: Là suy nghĩ của mô hình về những việc cần làm tiếp theo
Hành động: Là quyết định của mô hình về hành động cần thực hiện tiếp theo.
Đây là thời điểm lựa chọn công cụ có thể diễn ra
Trong hình ví dụ, một hành động có thể là một trong số [Flights/Chuyến bay, Search/Tìm kiếm, Code/Mã nguồn, None/Không chọn công cụ], trong đó 3 lựa chọn đầu tiên đại diện cho một công cụ đã biết mà mô hình có thể chọn, và lựa chọn cuối cùng, đại diện cho hành động “không chọn công cụ”.
Đầu vào hành động: Quyết định của mô hình về những đầu vào cần cung cấp cho công cụ (nếu có)
Quan sát: Kết quả của chuỗi hành động / đầu vào hành động
Chuỗi suy nghĩ => hành động => đầu vào hành động => quan sát này có thể lặp lại nhiều (N) lần nếu cần thiết.
- Câu trả lời cuối cùng: Câu trả lời cuối cùng của mô hình để cung cấp cho truy vấn gốc của người dùng
4. Vòng lặp ReAct (suy luận- hành động) kết thúc và câu trả lời cuối cùng được cung cấp lại cho người dùng.
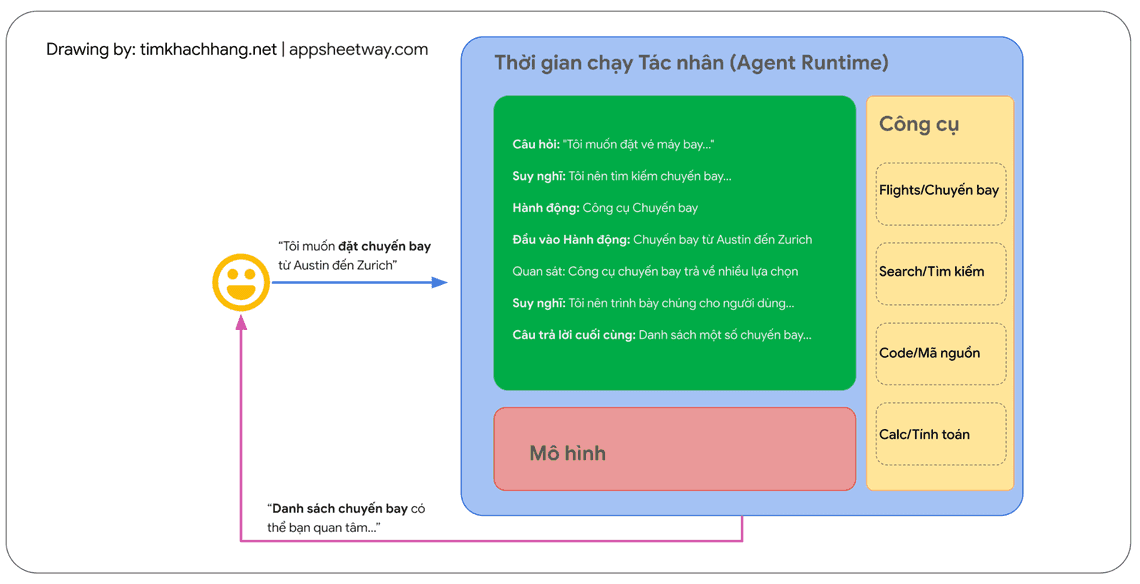
Như được thể hiện trong Hình 2, mô hình, công cụ và thiết lập cấu hình của tác nhân phối hợp với nhau để cung cấp phản hồi chính xác, súc tích cho người dùng dựa trên truy vấn gốc của họ. Trong khi mô hình có thể đoán biết câu trả lời (“đoán biết” về bản chất là trạng thái ảo giác) dựa trên kiến thức vốn có, thì thay vào đó, nó đã sử dụng một công cụ (Flights) để tìm kiếm thông tin bên ngoài theo thời gian thực. Thông tin bổ sung này được cung cấp cho mô hình, giúp mô hình đưa ra quyết định sáng suốt hơn dựa trên dữ liệu thực tế và tóm tắt thông tin này phản hồi lại cho người dùng.
Tóm lại, chất lượng phản hồi của tác nhân có thể được liên kết trực tiếp với khả năng lý luận và thực hiện hành động của mô hình với các nhiệm vụ khác nhau, bao gồm khả năng lựa chọn công cụ phù hợp, và mức độ hiệu quả của công cụ đó.
Giống như một đầu bếp chế biến một món ăn bằng nguyên liệu tươi ngon và chú ý đến phản hồi của khách hàng, tác nhân dựa vào khả năng lý luận chắc chắn và thông tin đáng tin cậy để đưa ra kết quả tối ưu. Trong phần tiếp theo, chúng ta sẽ đi sâu vào các cách khác nhau mà tác nhân kết nối với dữ liệu mới nhất.
Công cụ: Yếu tố then chốt để tác nhân vươn mình
Mặc dù mô hình ngôn ngữ có khả năng vượt trội trong việc xử lý thông tin, chúng lại thiếu khả năng trực tiếp cảm nhận và tác động đến thế giới thực. Điều này hạn chế tính hữu dụng của chúng trong các tình huống đòi hỏi tương tác với hệ thống hoặc dữ liệu bên ngoài. Điều này, trong chừng mực nào đó có thể hiểu rằng, mô hình ngôn ngữ chỉ tốt khi dựa trên những gì nó đã học được từ dữ liệu huấn luyện. Nhưng dù chúng ta có cung cấp cho mô hình bao nhiêu dữ liệu đi nữa, chúng vẫn thiếu khả năng cơ bản để tương tác với thế giới bên ngoài.
Vậy làm thế nào chúng ta có thể trao quyền cho mô hình của mình để nó có thể tương tác theo thời gian thực, và nhận biết ngữ cảnh với các hệ thống bên ngoài? Hàm (Functions), Tiện ích mở rộng (Extensions), Kho tri thức (Data Stores) và Phần mềm bổ sung (Plugin) là tất cả các phương thức để cung cấp khả năng thiết yếu này cho mô hình.
Dù được gọi bằng nhiều tên khác nhau, công cụ chính là yếu tố then chốt tạo ra liên kết giữa các mô hình ngôn ngữ nền tảng và thế giới bên ngoài. Việc liên kết với hệ thống và dữ liệu bên ngoài cho phép tác nhân của chúng ta thực hiện được các nhiệm vụ đa dạng hơn, và thực hiện điều đó với độ chính xác và tin cậy cao hơn. Ví dụ, công cụ có th�ể cho phép tác nhân điều chỉnh cài đặt nhà thông minh, cập nhật lịch, truy xuất thông tin người dùng từ cơ sở dữ liệu, hoặc gửi email dựa trên một tập hợp các chỉ thị cụ thể.
Tính đến thời điểm tài liệu này được phát hành, có ba loại công cụ chính mà mô hình Google có thể tương tác: Tiện ích mở rộng (Extensions), Hàm (Functions) và Kho dữ liệu (Data Stores). Bằng cách trang bị công cụ cho tác nhân, chúng ta mở ra một tiềm năng to lớn để các tác nhân không chỉ hiểu thế giới, mà còn tác động lên thế giới, mở ra cánh cửa đến vô vàn ứng dụng và khả năng mới chưa được khai phá.
Tiện ích mở rộng (Extensions)
Bạn có thể hiểu Tiện ích mở rộng (Extensions) một cách đơn giản như sau: Chúng là cầu nối giữa API (Giao diện lập trình ứng dụng) và tác nhân (Agent). Điều quan trọng là cầu nối này được chuẩn hóa. Nhờ vậy, tác nhân có thể sử dụng API một cách dễ dàng, liền mạch mà không cần quan tâm đến cách API đó được xây dựng và vận hành cụ thể như thế nào.
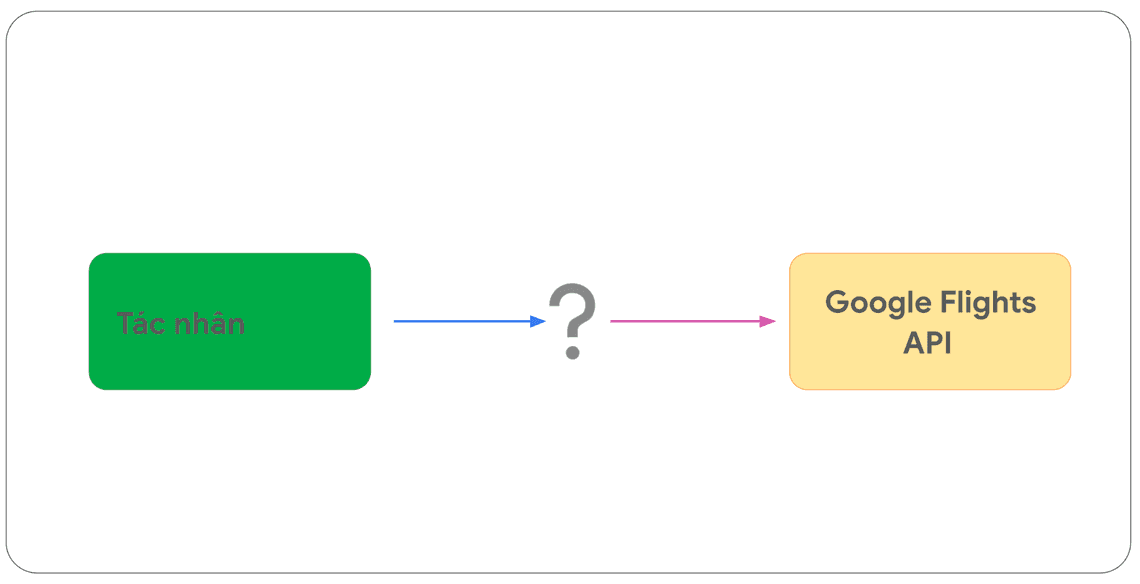
Hãy giả sử bạn đã xây dựng một tác nhân với mục tiêu là giúp người dùng đặt vé máy bay dựa trên thông tin mà người dùng nhập vào. Bạn đã biết rằng, bạn có thể sử dụng Google Flights API để truy xuất thông tin chuyến bay theo các tiêu chuẩn API đã xây dựng ra, nhưng bạn không chắc chắn làm thế nào để tác nhân của bạn có thể thay bạn thực hiện thành công lệnh gọi đến điểm cuối API (API endpoint) này.
Với cách tiếp cận triển khai mã nguồn tùy biến (custom code), mã nguồn có thể tiếp nhận các truy vấn đến từ người dùng, phân tích cú pháp truy vấn để tự động trích xuất thông tin liên quan và cần thiết theo tiêu chuẩn API đặt ra, sau đó thực hiện lại gọi API.
Hãy xem xét ví dụ sau về việc đặt vé máy bay:
Người dùng gửi một truy vấn: Tôi muốn đặt vé máy bay từ Austin đến Zurich. Trong trường hợp này, mã nguồn tùy biến sẽ trích xuất các thực thể liên quan có trong truy vấn của người dùng là Austin (nơi đi) và Zurich (nơi đến), trước khi thực hiện lệnh gọi API.
Nhưng điều gì sẽ xảy ra, nếu nội dung câu truy vấn của người dùng chỉ là: Tôi muốn đặt vé máy bay đến Zurich và không cung cấp thành phố nơi đi? Theo tiêu chuẩn, lệnh gọi API sẽ thất bại nếu thiếu dữ liệu bắt buộc (trong trường hợp này là thông tin “nơi đi”). Để vượt qua tình huống này, chúng ta cần phải viết thêm vào các trường hợp đặc biệt, ngoại lệ như vừa nêu, để mã nguồn tùy biến của chúng ta có thể hoạt động được. Tuy nhiên, cách tiếp cận này không có khả năng mở rộng và có thể dễ dàng gặp lỗi trong các trường hợp nằm ngoài khả năng tính toán của mã nguồn tùy biến đã triển khai.
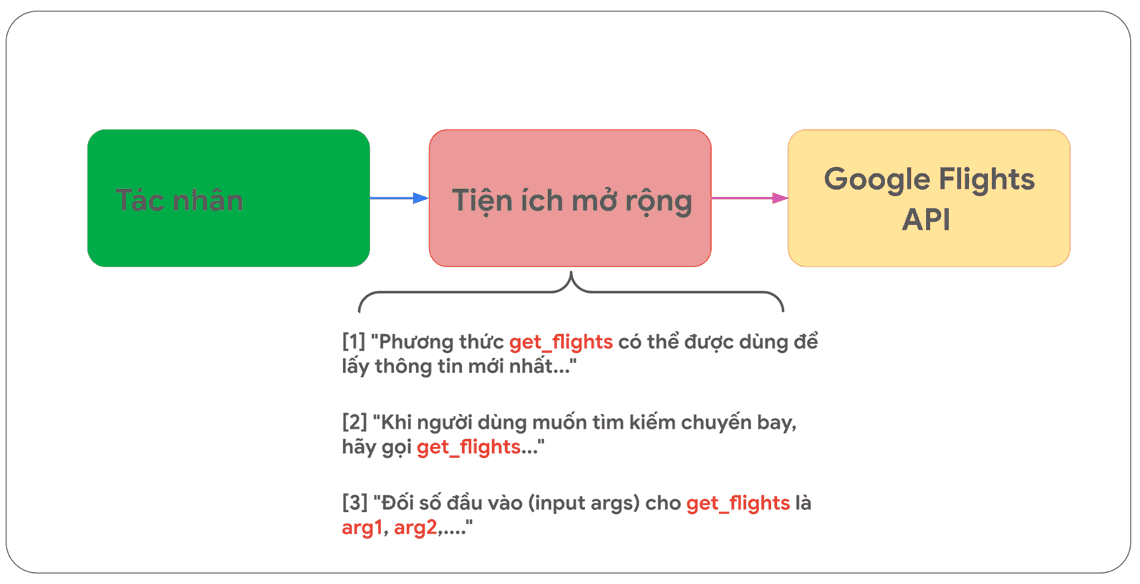
Một phương pháp linh hoạt hơn là sử dụng Tiện ích mở rộng. Tiện ích mở rộng thu hẹp khoảng cách giữa tác nhân và API bằng cách:
1. Dạy tác nhân cách sử dụng cách gọi đến các API thông qua các ví dụ.
2. Dạy tác nhân những đối số hoặc tham số nào là cần thiết để gọi API thành công.
Sau quá trình được đào tạo, tùy vào mục tiêu cần đạt được, tác nhân sẽ chủ động lựa chọn API cần gọi, lọc ra các tham số hoặc đối số có được từ sự phân tích, tổng hợp các truy vấn của người dùng.
Để hiểu rõ hơn tính linh hoạt của Tiện ích mở rộng, chúng ta hãy xem lại ví dụ đặt vé máy bay. Không như phương pháp mã nguồn tùy chỉnh, Tiện ích mở rộng cho phép tác nhân được dạy trước cách xử lý trong trường hợp các truy vấn thiếu thông tin. Ví dụ, tác nhân có thể được cấu hình để biết rằng thành phố khởi hành là thông tin bắt buộc cho khi gọi API đặt vé máy bay. Khi tác nhân nhận ra truy vấn của người dùng thiếu thành phố khởi hành, nó sẽ tự động hỏi lại để thu thập thông tin còn thiếu trước khi gọi API. Nhờ vậy, Tiện ích mở rộng trở nên linh hoạt và hiệu quả hơn trong việc xử lý các truy vấn không đầy đủ và đa dạng của người dùng.
Tiện ích mở rộng có thể được tạo ra độc lập với tác nhân, nhưng nó nên được cung cấp như một phần của cấu hình của tác nhân. Tác nhân sử dụng mô hình và các ví dụ được cung cấp vào thời điểm thực thi để quyết định loại Tiện ích mở rộng nào (nếu có), sẽ phù hợp để giải quyết truy vấn từ người dùng. Điều này làm nổi bật một ưu điểm chính của Tiện ích mở rộng, đó là các loại ví dụ được tích hợp sẵn, cho phép tác nhân chủ động lựa chọn một cách linh hoạt loại Tiện ích mở rộng phù hợp nhất cho nhiệm vụ cần hoàn thành trước mắt.
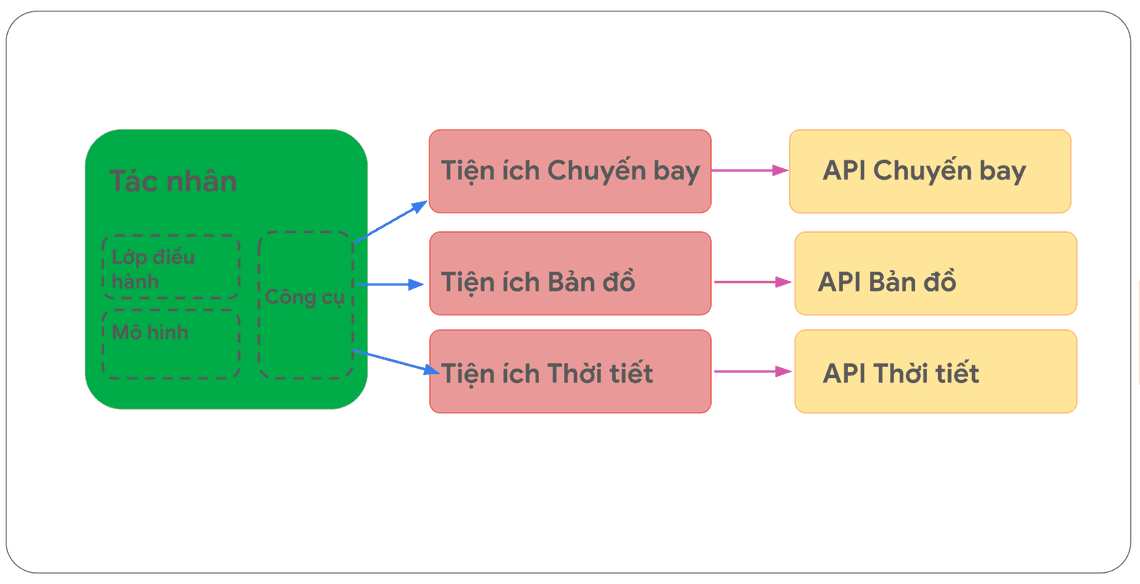
Hãy tưởng tượng điều này tương tự như cách một lập trình viên phát triển phần mềm, biết chủ động lựa chọn và quyết định sử dụng loại API nào là phù hợp nhất, trong quá trình tìm giải pháp cho vấn đề mà người dùng đặt ra. Nếu người dùng muốn đặt vé máy bay, nhà phát triển có thể sử dụng Google Flights API. Nếu người dùng muốn biết quán cà phê gần nhất nằm ở đâu so với vị trí của họ, nhà phát triển có thể sử dụng Google Maps API. Tương tự như vậy, các tác nhân / mô hình sử dụng một tập hợp các Tiện ích mở rộng đã biết từ trước, và tự quyết định Tiện ích mở rộng nào sẽ phù hợp nhất với truy vấn của người dùng tại thời điểm tác nhân thực thi nhiệm vụ.
Nếu bạn muốn xem cách Tiện ích mở rộng hoạt động, bạn có thể thử chúng trên ứng dụng Gemini bằng cách đi tới Cài đặt > Tiện ích mở rộng và sau đó bật bất kỳ Tiện ích mở rộng nào bạn muốn thử nghiệm. Ví dụ, bạn có thể bật Tiện ích mở rộng Google Flights, sau đó hỏi Gemini “Cho tôi xem chuyến bay từ Austin đến Zurich khởi hành vào thứ Sáu tới.”
Mẫu tiện ích mở rộng
Để đơn giản hóa việc sử dụng Tiện ích mở rộng, Google cung cấp một số Tiện ích mở rộng có sẵn, giúp bạn đưa các tiện ích nào vào trong dự án của bạn một cách nhanh chóng, sử dụng các cấu hình tối thiểu.
Tiện ích mở rộng Code Interpreter trong đoạn mã dưới đây, giúp tạo ra và chạy mã code Python từ một truy vấn nhập vào bằng ngôn ngữ tự nhiên.
Pythonimport vertexaiimport pprintPROJECT_ID = "YOUR_PROJECT_ID"REGION = "us-central1"vertexai.init(project=PROJECT_ID, location=REGION)from vertexai.preview.extensions import Extensionextension_code_interpreter = Extension.from_hub("code_interpreter")CODE_QUERY = """Write a python method to invert a binary tree in O(n) time."""response = extension_code_interpreter.execute(operation_id = "generate_and_execute",operation_params = {"query": CODE_QUERY})print("Generated Code:")pprint.pprint({response['generated_code']})# The above snippet will generate the following code.Generated Code:class TreeNode:def __init__(self, val=0, left=None, right=None):self.val = valself.left = leftself.right = rightdef invert_binary_tree(root):"""Inverts a binary tree.Args:root: The root of the binary tree.Returns:The root of the inverted binary tree."""if not root:return None# Swap the left and right children recursivelyroot.left, root.right =invert_binary_tree(root.right), invert_binary_tree(root.left)return root# Example usage:# Construct a sample binary treeroot = TreeNode(4)root.left = TreeNode(2)root.right = TreeNode(7)root.left.left = TreeNode(1)root.left.right = TreeNode(3)root.right.left = TreeNode(6)root.right.right = TreeNode(9)# Invert the binary treeinverted_root = invert_binary_tree(root)
Đoạn mã 1: Tiện ích mở rộng Code Interpreter có thể tạo ra và chạy mã Python code.
Tóm lại, Tiện ích mở rộng cung cấp một phương thức để tác nhân có thể nhận thức, tương tác và tác động đến thế giới bên ngoài theo nhiều cách khác nhau. Việc tác nhân lựa chọn và kích hoạt các Tiện ích mở rộng này được hướng dẫn bởi việc sử dụng các Ví dụ, và tất cả các ví dụ này được xác định như một phần của thiết lập cấu hình của Tiện ích mở rộng.
Hàm (Functions)
Trong thế giới về kỹ thuật phần mềm, hàm (functions) được định nghĩa là các mô-đun (module) mã nguồn khép kín thực hiện một nhiệm vụ cụ thể và có thể được tái sử dụng khi cần. Khi một nhà phát triển
phần mềm viết một chương trình, họ thường tạo ra nhiều hàm (functions) để thực hiện các tác vụ khác nhau. Họ cũng xác định logic cho thời điểm gọi hàm_a so với hàm_b, cũng như đầu vào và đầu ra dự kiến.
Hàm (functions) cũng hoạt động tương tự như vậy trong thế giới tác nhân, nhưng chúng ta có thể thay thế nhà phát triển phần mềm bằng một mô hình. Một mô hình có thể lấy một tập hợp các hàm (functions) đã biết và quyết định thời điểm sử dụng mỗi Hàm (Function) và các đối số mà Hàm (Function) cần dựa trên đặc điểm của nó.
Hai điểm khác biệt đáng chú ý nhất giữa Hàm (Functions) khác với Tiện ích mở rộng (Extensions) là:
1. Hàm và các đối số của nó (Function and its arguments) được tạo ra bởi Mô hình, nhưng cần Tiện ích mở rộng (Extensions) để hoạt động hiệu quả, ví dụ gọi API ra bên ngoài. Mô hình không tự thực hiện lệnh gọi API, nhiệm vụ của mô hình là quyết định và hướng dẫn lựa chọn sử dụng hàm nào và dừng lại ở đó.
2. Hàm (Functions) được thực thi ở phía máy khách (client-side), trong khi Tiện ích mở rộng được thực thi ở phía tác nhân (agent-side).
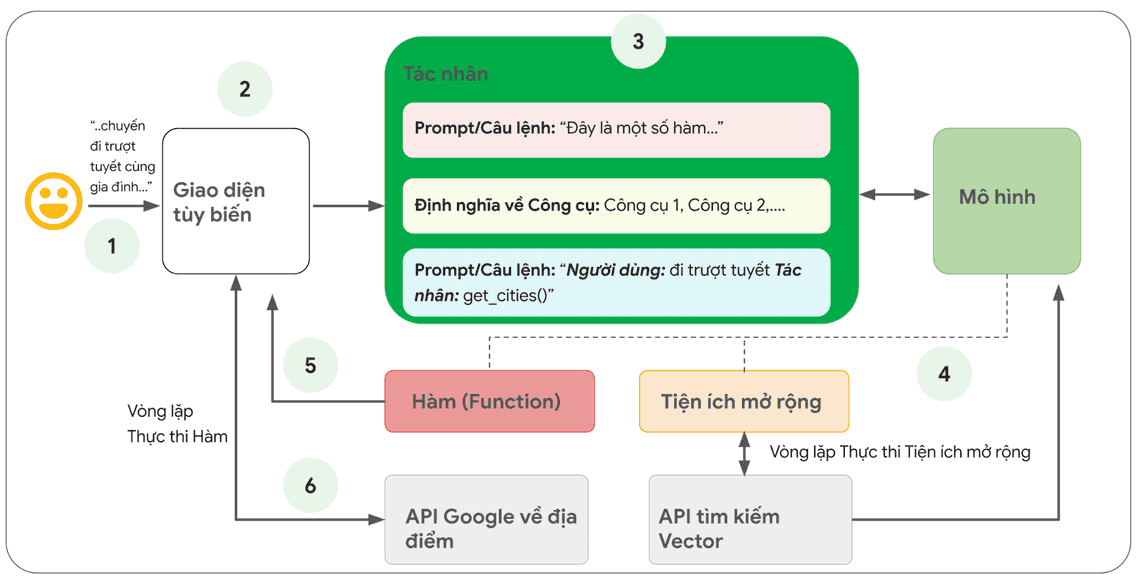
Hình dưới đây mô phỏng thiết lập cho hàm với tình huống sử dụng Google Flights đã nêu trước đây. (Hình 7)
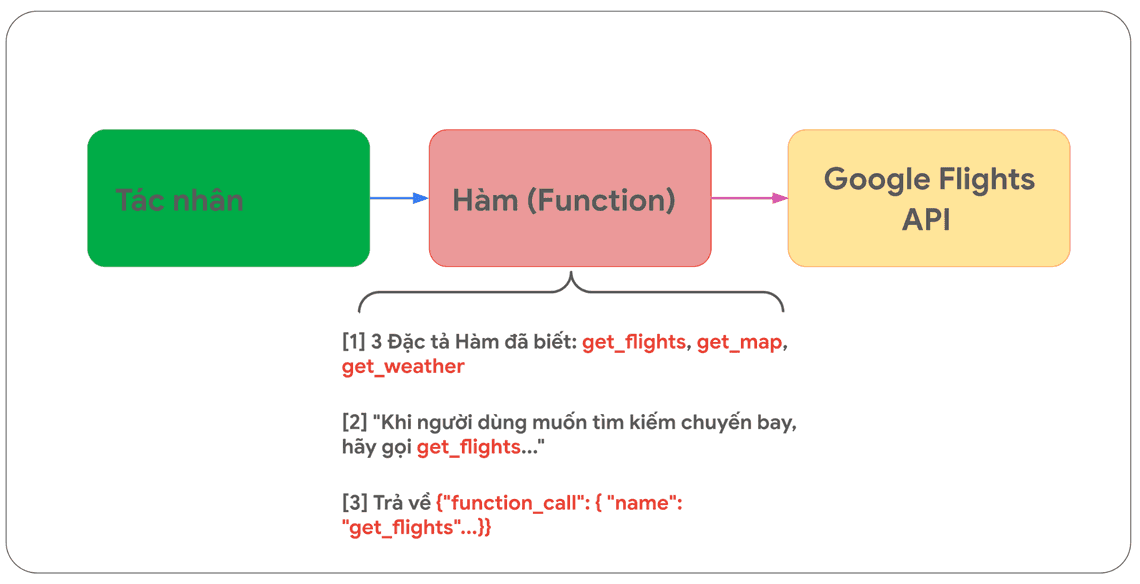
Cần đặc biệt lưu ý sự khác biệt quan trọng nhất là cả Hàm (Function) và tác nhân (Agent) đều không tương tác trực tiếp với Google Flights API. Điều này dẫn đến một câu hỏi then chốt. Vậy quá trình gọi API sẽ thực sự diễn ra như thế nào khi tác nhân hoạt động?
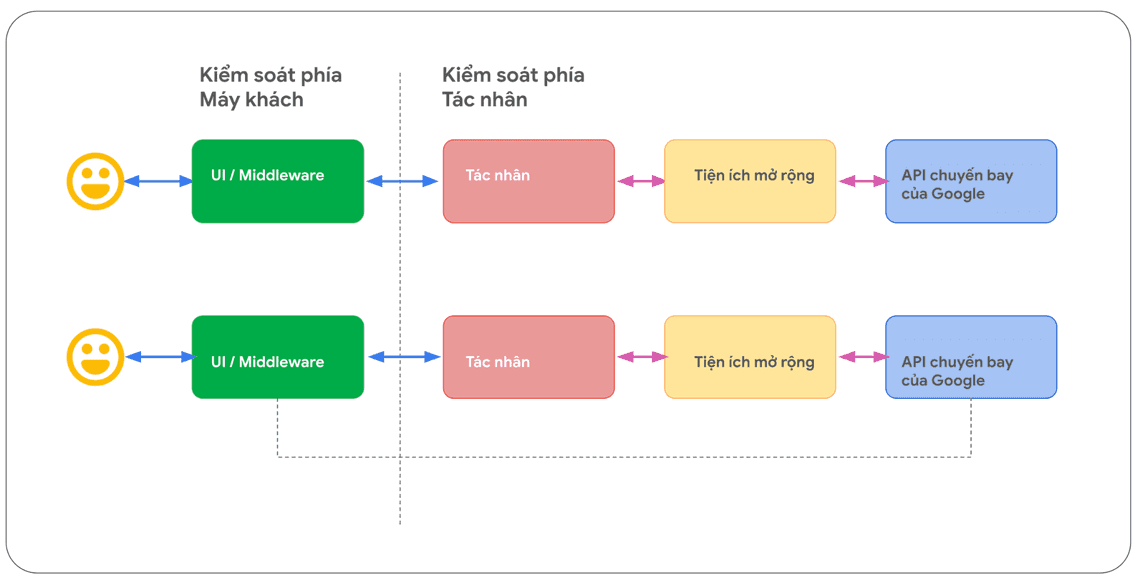
Với hàm (functions), logic và việc thực thi lệnh gọi API thực tế được chuyển ra khỏi tác nhân và trở lại ứng dụng phía máy khách (client-side) như trong Hình 8 và Hình 9 bên dưới.
Điều này mang lại cho nhà phát triển phần mềm khả năng kiểm soát chi tiết hơn về các luồng dữ liệu bên trong ứng dụng. Có nhiều lý do tại sao Nhà phát triển phần mềm có thể chọn sử dụng hàm (Functions) thay vì Tiện ích mở rộng(Extensions), nhưng một vài trường hợp sử dụng phổ biến là:
Các lệnh gọi API cần được thực hiện ở một lớp khác trong kiến trúc của ứng dụng, lớp này nằm bên ngoài luồng kiến trúc tác nhân trực tiếp, ví dụ: nằm ở hệ thống trung gian (a middleware system), hoặc các nền tảng tạo giao diện ứng dụng (framework front-end), .v.v.
Các giới hạn về bảo mật hoặc xác thực trên các hệ thống khác nhau, có thể ngăn tác nhân trực tiếp gọi API. Ví dụ: API không được hiển thị trên internet hoặc bị ngăn chặn và không thể truy cập được bởi nhà cung cấp cơ sở hạ tầng xây dựng tác nhân.
Các ràng buộc về thời gian hoặc thứ tự thao tác, ngăn chặn tác nhân thực hiện lệnh gọi API trong thời gian thực. Ví dụ: ràng buộc về số thao tác hàng loạt tại một thời điểm, các đánh giá yêu cầu có sự tham gia của con người trước khi tiến hành hành động kế tiếp .v.v.
Cần áp dụng logic chuyển đổi dữ liệu bổ sung cho các phản hồi từ API mà tác nhân không thể tự thực hiện được. Ví dụ: Nếu một API không cung cấp cơ chế lọc để giới hạn số lượng kết quả trả về. Sử dụng Hàm (Functions) ở phía máy khách (client-side) trong trường hợp này, cung cấp cho nhà phát triển các cơ hội bổ sung cơ chế lọc kết quả và vượt qua hạn chế được thiết lập từ trước của API nói trên.
Nhà phát triển mong muốn có thể nhanh chóng cải tiến và thay đổi tác nhân AI của họ một cách lặp đi lặp lại, và họ muốn thực hiện việc này mà không cần triển khai thêm cơ sở hạ tầng phức tạp cho các API. Giải pháp Gọi hàm (Function Calling) hỗ trợ việc này vì nó cho phép nhà phát triển sử dụng một kỹ thuật tương tự như “stubbing” API.
Mặc dù sự khác biệt trong kiến trúc nội bộ giữa hai phương pháp là rất nhỏ như được thấy trong
Hình 8, nhưng khả năng kiểm soát bổ sung và sự phụ thuộc tách rời vào cơ sở hạ tầng bên ngoài khiến giải pháp Gọi hàm (Function Calling) từ phía máy khách (client-side) trở thành một lựa chọn hấp dẫn cho Nhà phát triển.
Các trường hợp sử dụng
Một mô hình có thể được sử dụng để gọi hàm (functions) xử lý các luồng thực thi phức tạp ở phía máy khách (client-side) theo yêu cầu từ người dùng cuối, trong khi đó Nhà phát triển tác nhân có thể không muốn mô hình ngôn ngữ quản lý việc thực thi API (như trường hợp với Tiện ích mở rộng).
Hãy xem xét ví dụ sau: Bạn đang đào tạo một tác nhân đóng vai trò trợ lý du lịch để tương tác với những người dùng muốn đặt các chuyến du lịch nghỉ dưỡng. Mục tiêu của bạn, là làm sao tác nhân có thể tạo ra danh sách các thành phố mà bạn có thể sử dụng trong ứng d�ụng trung gian của bạn, sau đó tải xuống hình ảnh và dữ liệu khác liên quan đến các thành phố và biến các dữ liệu này thành đầu vào của việc lập kế hoạch chuyến đi cho người dùng. Nhưng một người dùng có thể viết một yêu cầu như sau:
Tôi muốn đi trượt tuyết với gia đình như tôi không chắc nên đi đến đâu.
Mô hình lúc này có thể trả về kết quả như dưới đây:
Chắc chắn rồi. Dưới đây là danh sách các thành phố bạn có thể cân nhắc cho kỳ nghỉ trượt tuyết của gia đình.
• Crested Butte, Colorado, Hoa Kỳ
• Whistler, BC, Canada
• Zermatt, Thụy Sĩ
Mặc dù kết quả trả về nêu trên có chứa dữ liệu mà bạn cần (tên thành phố), nhưng đây không phải là định dạng lý tưởng nhất cho việc phân tích cú pháp. Với phương pháp Gọi hàm (Function Calling), chúng ta có thể dạy mô hình định dạng đầu ra này theo kiểu có cấu trúc (như JSON), và thuận tiện hơn cho một hệ thống khác trong việc phân tích cú pháp. Với cùng một câu lệnh từ người dùng, đầu ra theo định dạng JSON lấy ra từ Hàm (Function) nhìn sẽ giống như dưới đây.
function_call {name: "display_cities"args: {"cities": ["Crested Butte", "Whistler", "Zermatt"],"preferences": "skiing"}}
Payload Gọi hàm (Function Call) mẫu để hiển thị danh sách các thành phố và tùy chọn của người dùng
Payload với format JSON này, được tạo bởi mô hình và sau đó được gửi đến máy chủ phía máy khách (Client-side) của bạn để thực hiện bất cứ điều gì bạn muốn làm với nó. Trong trường hợp cụ thể này, bạn sẽ gọi tiếp Google Places API để lấy các thành phố do mô hình cung cấp và tra cứu Hình ảnh, sau đó cung cấp các hình ảnh chúng dưới dạng nội dung đa phương tiện và trả về cho Người dùng của bạn. Hãy xem xét sơ đồ tuần tự trong Hình 9 hiển thị tương tác trên theo từng bước chi tiết.
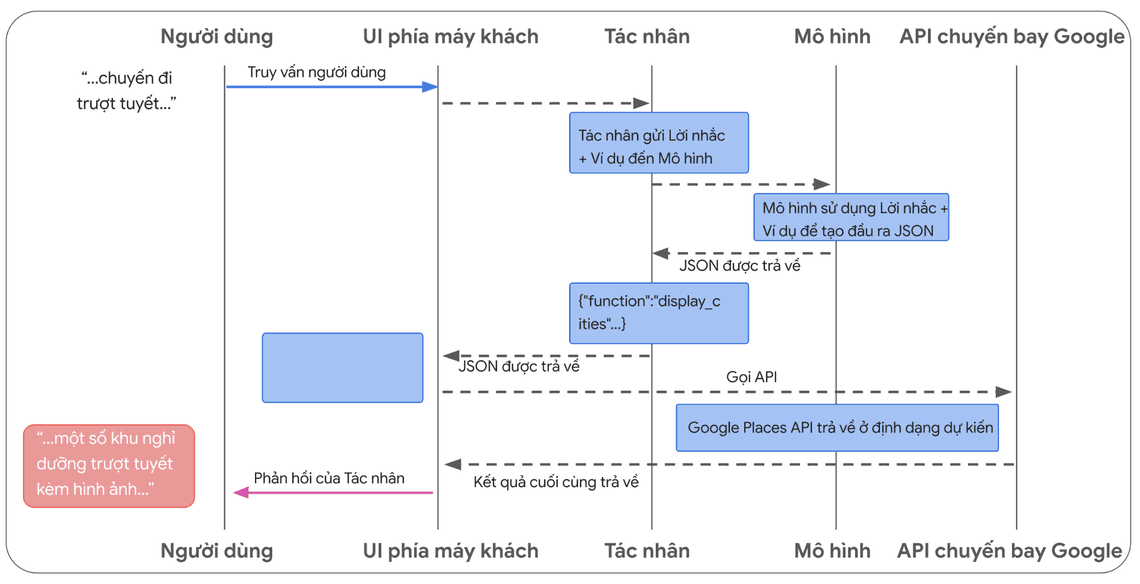
Kết quả của ví dụ trong Hình 9 là mô hình được sử dụng để “điền vào chỗ trống” với các tham số cần thiết để giao diện phía máy khách (Client side UI) thực hiện được lệnh gọi đến Google Places API.
Giao diện máy máy khách (Client side UI) đóng vai trò quản lý lệnh gọi API thực tế, bằng cách sử dụng các tham số do chính mô hình cung cấp trong Hàm (Function) được trả về. Đây chỉ là một ví dụ sử dụng Gọi hàm (Function Calling), trên thực tế, có nhiều trường hợp khác cần xem xét như:
Bạn muốn một mô hình ngôn ngữ đề xuất một hàm (function) mà bạn có thể sử dụng trong mã code do bạn viết ra, nhưng đồng thời bạn lại không muốn đưa thông tin xác thực vào mã của mình. Vì phương thức gọi hàm (function calling) không chạy trực tiếp hàm (function), do đó, bạn không cần đưa thông tin xác thực vào mã code của bạn cùng với thông tin hàm (function).
Bạn đang chạy các thao tác được thực thi không đồng bộ, điều có thể mất hơn vài giây. Các trường hợp này hoạt động tốt với phương thức gọi hàm (function calling) bởi vì bản chất đó là một tác một thao tác không đồng bộ.
Bạn muốn chạy hàm (functions) trên một thiết bị khác so với hệ thống tạo ra các lệnh gọi hàm (function calls) và đối số của chúng.
Một điều quan trọng cần nhớ về hàm (functions) là chúng được dùng để cung cấp cho nhà phát triển khả năng kiểm soát nhiều hơn cả về việc thực thi các lệnh gọi API, cũng như toàn bộ các luồng dữ liệu bên trong ứng dụng. Trong ví dụ ở Hình 9, nhà phát triển đã chọn cách không trả về thông tin API cho tác tác nhân, vì nó có thể không liên quan đến các hành động trong tương lai mà tác nhân cần thực hiện. Tuy nhiên, dựa trên kiến trúc đặc thù của từng ứng dụng, có thể cũng có ý nghĩa khi dữ liệu trả về từ lệnh gọi API ở bên ngoài cho tác nhân, có tác động đến khả năng lý luận, logic và lựa chọn hành động trong tương lai của tác nhân. Đến tận cùng, nhà phát triển ứng dụng vẫn là bên quyết định điều gì là phù hợp với từng ứng dụng cụ thể.
Mã nguồn mẫu cho Hàm
Để đạt được đầu ra như đ��ề cập ở trên cho tình tình huống về kỳ nghỉ trượt tuyết, bây giờ chúng ta sẽ xây dựng xây dựng từng thành phần và làm chu trình hoạt động bằng cách sử dụng mô hình google gemini-1.5-flash-001.
Đầu tiên, chúng ta sẽ định nghĩa hàm (function) display_cities bằng một đoạn mã code Python đơn giản dưới đây.
# Pythondef display_cities(cities: list[str], preferences: Optional[str] = None):"""Provides a list of cities based on the user's search query and preferences.Args:preferences (str): The user's preferences for the search, like skiing,beach, restaurants, bbq, etc.cities (list[str]): The list of cities being recommended to the user.Returns:list[str]: The list of cities being recommended to the user."""return cities
Đoạn mã 6: Mã code python để hàm hiển thị danh sách thành phố.
Tiếp theo, chúng ta sẽ khởi tạo mô hình, xây dựng Công cụ, sau đó đưa truy vấn và công cụ của người dùng vào mô hình.
Thực thi đoạn mã bên dưới đây…
Pythonfrom vertexai.generative_models import GenerativeModel, Tool, FunctionDeclarationmodel = GenerativeModel("gemini-1.5-flash-001")display_cities_function = FunctionDeclaration.from_func(display_cities)tool = Tool(function_declarations=[display_cities_function])message = "I'd like to take a ski trip with my family but I'm not sure whereto go."res = model.generate_content(message, tools=[tool])print(f"Function Name: {res.candidates[0].content.parts[0].function_call.name}")print(f"Function Args: {res.candidates[0].content.parts[0].function_call.args}")
Đoạn mã 7: Xây dựng Công cụ, gửi truy vấn người dùng đến mô hình để thực hiện lệnh gọi hàm
…sẽ tạo ra đầu ra như sau:
> Function Name: display_cities> Function Args: {'preferences': 'skiing', 'cities': ['Aspen', 'Vail','Park City']}
Tóm lại, hàm (functions) cung cấp một khuôn mẫu làm việc đơn giản, cho phép các nhà phát triển ứng dụng có thể kiểm soát chi tiết các luồng dữ liệu và quá trình hệ thống thực thi các tác vụ, đồng thời tận dụng hiệu quả sức mạnh của tác nhân/mô hình để tạo đầu vào quan trọng. Sử dụng hàm, Nhà phát triển có thể tùy chọn liệu có nên giữ tác nhân “trong vòng lặp” bằng cách trả về hoặc không trả về dữ liệu từ bên ngoài dựa trên các yêu cầu kiến trúc ứng dụng cụ thể.
Kho tri thức
Hãy tưởng tượng một mô hình ngôn ngữ, giống như một thư viện sách khổng lồ, chứa dữ liệu mà nó được đào tạo. Tuy nhiên, khác với thư viện sách thường xuyên được bổ sung, “thư viện mô hình” này tĩnh tại, chỉ chứa kiến thức từ dữ liệu huấn luyện ban đầu. Điều này tạo ra một thách thức, vì trong thực tế, kiến thức thế giới ngoài đời thực liên tục phát triển. Kho tri thức (Data stores) là giải pháp then chốt để vượt qua hạn chế này. Chúng cung cấp quyền truy cập vào thông tin động, cập nhật, và đảm bảo phản hồi của mô hình luôn xác thực và liên quan.
Dưới đây một tình huống phổ biến, trong đó nhà phát triển có thể cần cung cấp một lượng nhỏ dữ liệu bổ sung cho mô hình, thông thường cung cấp dưới dạng bảng tính (Google Sheets, Excel) hoặc file PDF.
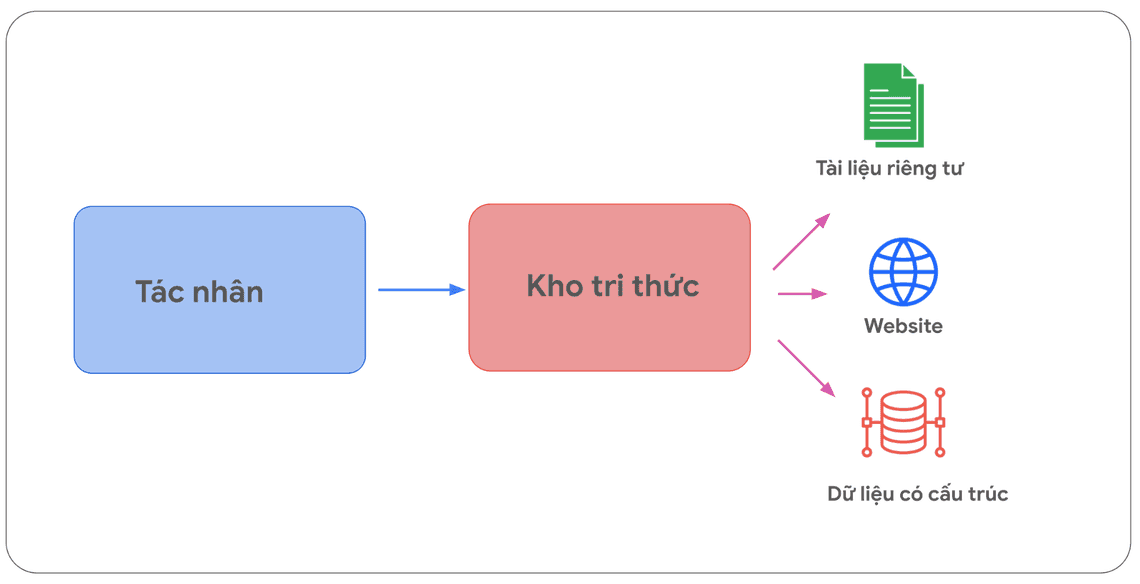
Kho tri thức (Data Stores) cho phép nhà phát triển ứng dụng cung cấp dữ liệu bổ sung ở định dạng gốc của nó cho một tác nhân, giúp loại bỏ nhu cầu chuyển đổi dữ liệu vốn tốn thời gian, đào tạo lại hoặc tinh chỉnh mô hình.
Kho tri thức (Data Stores) chuyển đổi tài liệu đầu vào thành tập hợp các vectơ nhúng trong cơ sở dữ liệu vector. Tác nhân có thể sử dụng các vectơ nhúng này để trích xuất thông tin cần thiết. Thông tin này sẽ bổ sung cho các hành động tiếp theo hoặc phản hồi của tác nhân cho người dùng.
Triển khai và ứng dụng
Trong lĩnh vực tác nhân AI tạo sinh (Generative AI agents), Kho tri thức (Data Stores) thường được triển khai dưới dạng cơ sở dữ liệu vector (vector database). Đây là loại cơ sở dữ liệu mà nhà phát triển muốn cung cấp cho tác nhân quyền truy cập trong quá trình thực thi nhiệm vụ.
Ở đây, chúng ta sẽ không đi vào chi tiết về cơ sở dữ liệu vector. Điểm mấu chốt cần nhớ về cơ sở dữ liệu vector, là chúng lưu trữ dữ liệu dưới dạng embedding vector, vốn là một loại vector đa chiều, hay còn gọi là biểu diễn toán học của dữ liệu đầu vào. Một trong những ví dụ điển hình nhất về việc sử dụng Kho tri thức (Data Store) với các mô hình ngôn ngữ trong thời gian gần đây, là việc triển khai các ứng dụng RAG - Retrieval Augmented Generation - Ứng dụng tạo sinh Tăng cường Truy xuất thông tin theo thời gian thực.
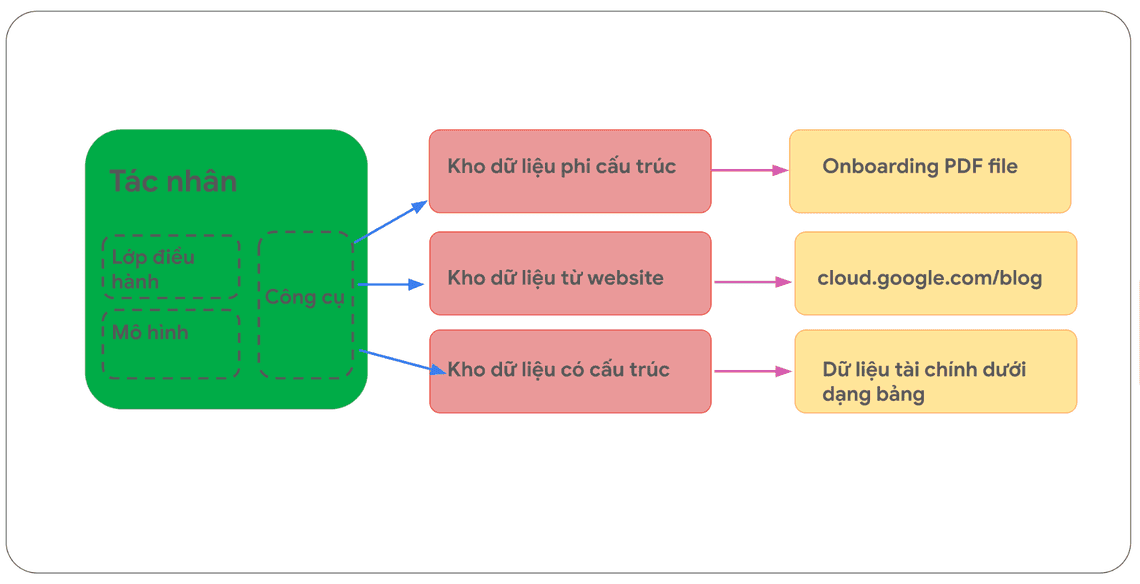
Các ứng dụng này hướng đến việc mở rộng cả bề rộng lẫn chiều sâu kiến thức của mô hình. Mục tiêu là giúp mô hình vượt qua giới hạn dữ liệu huấn luyện ban đầu, bằng cách cấp quyền truy cập vào kho dữ liệu với nhiều định dạng khác nhau, ví dụ như:
Nội dung website
Dữ liệu có cấu trúc ở các định dạng như PDF, Word Docs, CSV, Bảng tính (Excel, Google Sheets), v.v.
Dữ liệu phi cấu trúc ở các định dạng như HTML, PDF, TXT, v.v.
Mô hình tổng quát về quy trình xử lý mỗi yêu cầu người dùng và vòng lặp phản hồi của tác nhân được thể hiện trong Hình 13
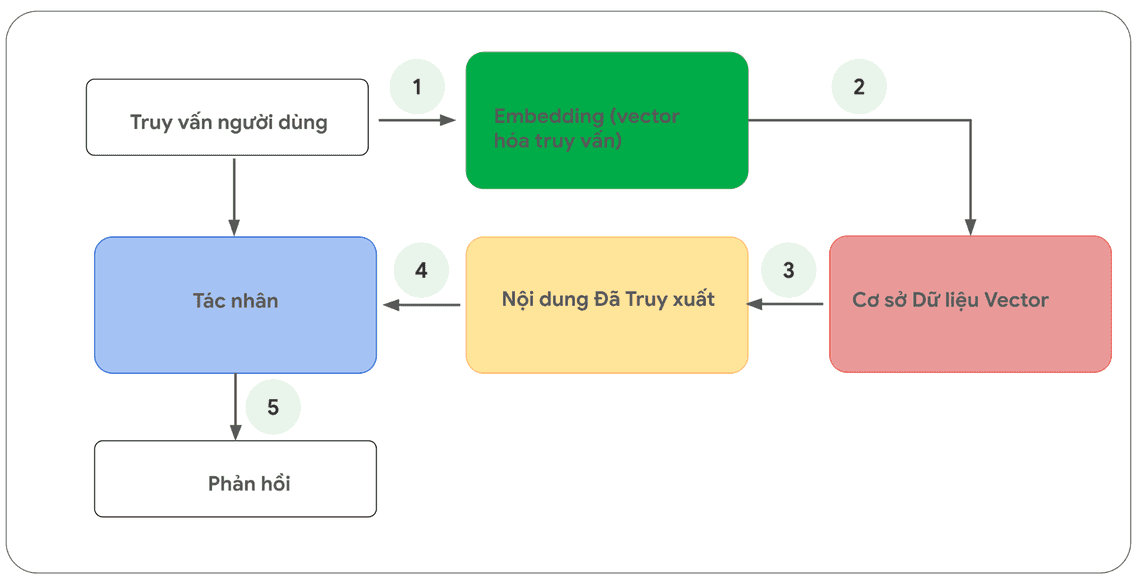
1. Truy vấn của người dùng được gửi đến mô hình nhúng (embedding) để vector hóa truy vấn - vốn là ngôn ngữ tự nhiên của con người.
2. Sau đó, các truy vấn đã được vector hóa (embedding truy vấn) được đem đối sánh với nội dung cơ sở dữ liệu vector thông qua các thuật toán so khớp vector, ví dụ như SCaNN.
3. Nội dung cần so khớp được truy xuất từ cơ sở dữ liệu vector ở trạng thái định dạng văn bản và gửi trả lại cho tác nhân.
4. Tác nhân nhận được cả truy vấn của người dùng và nội dung đã truy xuất, sau đó xây dựng phản hồi hoặc hành động
5. Phản hồi cuối cùng được gửi đến người dùng
Kết quả cuối cùng, chúng ta có ứng dụng cho phép tác nhân so khớp giữa truy vấn của người dùng với một kho tri thức (data stores) bằng phương pháp tìm kiếm vector, truy xuất nội dung gốc và cung cấp nội dung đó cho lớp điều hành và mô hình để xử lý. Hành động tiếp theo có thể là cung cấp câu trả lời cuối cùng cho người dùng hoặc thực hiện tìm kiếm vector bổ sung, để tinh chỉnh thêm kết quả.
Bảng tổng kết về công cụ
Tóm lại, Tiện ích mở rộng (Extensions), Hàm (functions) và Kho tri thức (data stores) tạo thành các loại công cụ khác nhau, sẵn sàng để tác nhân sử dụng vào thời điểm thực thi nhiệm vụ. Mỗi công cụ có mục đích riêng, có thể được sử dụng cùng nhau hoặc độc lập, tùy theo quyết định của nhà phát triển tác nhân.
| Tiện ích mở rộng | Gọi hàm | Kho Tri thức | |
| Thực thi | Phía Tác nhân (Agent-Side Execution) | Phía Máy Khách (Client-Side Execution) | Phía Tác nhân (Agent-Side Execution) |
| Trường hợp sử dụng | - Nhà phát triển muốn tác nhân kiểm soát quá trình tương tác với các API - Hữu ích khi tận dụng được các Tiện ích mở rộng đã xây dựng sẵn (ví dụ: Vertex Search, Code Interpreter, v.v.) - Lập kế hoạch đa bước và gọi API (ví dụ: hành động tiếp theo của tác nhân phụ thuộc vào đầu ra của hành động / lệnh gọi API trước đó) | - Các hạn chế về bảo mật hoặc xác thực ngăn tác nhân gọi API trực tiếp. - Các ràng buộc về thời gian hoặc trình tự thao tác ngăn tác nhân thực hiện lệnh gọi API trong thời gian thực (ví dụ: thao tác hàng loạt, các đánh giá yêu cầu bắt buộc có sự tham gia của con người .v.v.) - Thông tin API không được công khai trên internet hoặc API không cho được phép truy cập bởi chính sách của các hệ thống phát triển tác nhân ví dụ như của Google. | Nhà phát triển muốn triển khai Tạo sinh Tăng cường Truy xuất (RAG) với các dữ liệu sau: - Nội dung Website/Link đã được lập chỉ mục trước • Dữ liệu có cấu trúc ở các định dạng như PDF, Word Docs, CSV,Excel, Google Sheets v.v. • Cơ sở dữ liệu Quan hệ / Phi Quan hệ • Dữ liệu phi cấu trúc ở các định dạng như HTML, PDF, TXT, v.v. |
Nâng cao hiệu suất mô hình nhờ học tập có mục tiêu
Đào tạo tổng quát là điểm khởi đầu tốt, trang bị cho mô hình những năng lực cơ bản. Tuy nhiên, điều đó là chưa đủ để mô hình AI thực sự hiệu quả trong các ứng dụng thực tế, đặc biệt là những ứng dụng phức tạp, chuyên biệt và đòi hỏi sử dụng công cụ bên ngoài (như Tiện ích mở rộng hoặc Hàm).
Hãy nghĩ việc học của các mô hình AI cũng giống như bạn đang học để trở thành một đầu bếp. Để nấu được món ăn, bạn chỉ cần được huấn luyện các kỹ năng cơ bản về nấu nướng. Điều này tương tự như quá trình đào tạo kiến thức tổng quát cho mô hình AI.
Nhưng nếu mục tiêu của bạn, là trở thành một đầu bếp bậc thầy về một số món ăn của một nền ẩm thực nào đó, ví dụ là các món ăn Nhật Bản, bạn cần được đào tạo chuyên sâu về ẩm thực Nhật Bản. Tương tự như vậy, nếu muốn mô hình AI thực sự giỏi trong thực thi các nhiệm vụ cụ thể, phức tạp ngoài đời thật, mô hình AI cũng cần được đào tạo chuyên sâu hơn.
Dưới đây là một số phương pháp tiếp cận để đào tạo chuyên sâu cho các mô hình AI:
Học tập trong ngữ cảnh (In-context learning): Phương pháp này cung cấp cho mô hình tổng quát một lời nhắc (prompt), các công cụ và một vài ví dụ minh họa (few-shot examples) tại thời điểm suy luận, cho phép mô hình học “ngay lập tức” về cách thức và thời điểm sử dụng các công cụ đó cho một nhiệm vụ cụ thể. Khuôn mẫu lý luận ReAct là một ví dụ về phương pháp tiếp cận này trong ngôn ngữ tự nhiên.
Học tập trong ngữ cảnh dựa trên truy xuất (Retrieval-based in-context learning): Kỹ thuật này hoạt động bằng cách tự động đưa vào câu lệnh (prompt) của mô hình những thông tin, công cụ và ví dụ minh họa phù hợp nhất, được trích xuất từ bộ nhớ ngoài. Ví dụ điển hình cho phương pháp này là “Ngân hàng Ví dụ Mẫu” trong Vertex AI, hoặc các kho tri thức (data stores) theo kiến trúc RAG đã được đề cập trước đó
Học tập dựa trên tinh chỉnh (Fine-tuning based learning): Phương pháp này bao gồm việc huấn luyện mô hình trên một tập dữ liệu lớn hơn, chứa các ví dụ cụ thể, trước khi mô hình thực hiện suy luận. Điều này giúp mô hình hiểu được thời điểm và cách thức áp dụng các công cụ cụ thể, trước cả khi nhận được bất kỳ truy vấn nào từ người dùng.
Để làm rõ hơn về từng phương pháp học tập có mục tiêu, hãy cùng xem lại ví dụ mô phỏng cách học nấu ăn đã nêu trên để minh họa rõ hơn về sự khác nhau giữa phương pháp đào tạo mô hình vừa nêu.
- Hãy tưởng tượng bạn là một đầu bếp, và khách hàng cung cấp cho bạn một số thông tin hạn chế, bao gồm: (1) một công thức món ăn, (2) một vài nguyên liệu chính, và (3) vài món ăn mẫu.
Với vai trò là đầu bếp, vốn có các hiểu biết về các kiến thức nấu ăn tổng quát, bạn vẫn phải “ứng biến” để chế biến món ăn sao cho phù hợp nhất với công thức và sở thích của khách hàng. Đây chính là học tập trong ngữ cảnh (in-context learning). Trong ví dụ này, công thức món ăn cụ thể đóng vai trò như câu lệnh (the prompt), các nguyên vật liệu chính giống như các công cụ liên quan (relevant tools), và các ví dụ về món ăn giống như là các ví dụ mẫu mà mô hình cần (few-shot examples).
Hãy tiếp tục tưởng tượng, bạn vẫn là đầu bếp và đang đứng trong một nhà bếp có một tủ đựng thức ăn đầy ắp chứa đầy đủ các nguyên liệu và các loại sách dạy nấu ăn khác nhau, mỗi trang sách bao gồm món ăn và thành phần chế biến tương ứng. Trong tình huống này, bạn có thể linh hoạt lựa chọn nguyên liệu, sách nấu ăn và chủ động điều chỉnh tốt hơn theo công thức và sở thích của khách hàng. Điều này cho phép bạn tạo ra món ăn tinh tế hơn, vì bạn đã dựa trên nhiều thông tin hơn, và tận dụng được cả kiến thức hiện có và kiến thức mới. Đây là học tập trong ngữ cảnh dựa trên truy xuất (retrieval-based in-context learning). Trong ví dụ này, các nguyên liệu và sách dạy nấu ăn đóng vai trò như công cụ và ví dụ mẫu (examples and tools), còn nhà bếp bạn đang đứng đóng vai trò như kho tri thức (external data stores).
Cuối cùng, hãy hình dung, dù đã là đầu bếp chuyên nghiệp, bạn vẫn được nhà hàng cử đi học nâng cao để tìm hiểu một nền ẩm thực mới, hoặc tham gia các khóa đào tạo để làm phong phú thêm thực đơn. Quá trình này cho giúp bạn biết hoặc tiếp cận thêm các công thức nấu ăn của khách hàng mà bạn chưa từng thấy trước đó (sẽ thấy trong tương lai) và đồng thời, bạn cũng được trang bị sự hiểu biết sâu sắc về các yêu cầu này của khách hàng. Phương pháp tiếp cận này rất phù hợp nếu mục tiêu đặt ra, là bạn muốn trở nên vượt trội trong các nền ẩm thực cụ thể (kiến thức chuyên sâu về nền ẩm thực đó). Đây là học tập dựa trên tinh chỉnh (fine-tuning based learning).
Mỗi phương pháp tiếp cận nêu trên mang lại những ưu điểm và nhược điểm riêng về tốc độ, chi phí và độ trễ trong quá trình phản hồi. Tuy nhiên, bằng cách kết hợp các kỹ thuật này trong một khuôn mẫu về phát triển tác nhân (agent framework), chúng ta có thể tận dụng các điểm mạnh khác nhau và giảm thiểu điểm yếu của chúng, từ đó tạo ra một giải pháp mạnh mẽ và dễ thích ứng hơn với yêu cầu thực tế.
Tạo nhanh tác nhân với LangChain
Để cung cấp ví dụ thực tế về xây dựng một tác nhân, chúng ta sẽ bắt tay xây dựng một tác nhân mẫu bằng cách sử dụng các thư viện LangChain và LangGraph. Đây là các thư viện mã nguồn mở cho phép nhà phát triển xây dựng tác nhân bằng cách xâu chuỗi các logic, lý luận và gọi ra công cụ liên quan để trả lời truy vấn của người dùng.
Trong ví dụ này, chúng ta sẽ sử dụng mô hình gemini-1.5-flash-001 và một số công cụ đơn giản để trả lời một truy vấn nhiều bước từ người dùng như trong Đoạn mã 8 dưới đây.
Các công cụ chúng ta sẽ sử dụng là SerpAPI (cho Google Search) và Google Places API. Sau khi thực thi chương trình trong Đoạn mã 8, bạn sẽ thấy đầu ra mẫu trong Đoạn mã 9.
#Pythonfrom langgraph.prebuilt import create_react_agentfrom langchain_core.tools import toolfrom langchain_community.utilities import SerpAPIWrapperfrom langchain_community.tools import GooglePlacesToolos.environ["SERPAPI_API_KEY"] = "XXXXX"os.environ["GPLACES_API_KEY"] = "XXXXX"@tooldef search(query: str):"""Sử dụng SerpAPI để chạy tìm kiếm Google."""search = SerpAPIWrapper()return search.run(query)@tooldef places(query: str):"""Sử dụng Google Places API để chạy truy vấn Google Places."""places = GooglePlacesTool()return places.run(query)model = ChatVertexAI(model="gemini-1.5-flash-001")tools = [search, places]query = "Đội Texas Longhorns đã đấu với đội nào trong trận bóng bầu dục tuần trước? Địa chỉsân vận động của đội kia là gì?"agent = create_react_agent(model, tools)input = {"messages": [("human", query)]}for s in agent.stream(input, stream_mode="values"):message = s["messages"][-1]if isinstance (message, tuple):print(message)else:message.pretty_print()
Đoạn mã 8. Mẫu tác nhân dựa trên LangChain và LangGraph với các công cụ.
#Python======================== Tin nhắn từ Người dùng =========================Đội Texas Longhorns đã đấu với đội nào trong trận bóng bầu dục tuần trước? Địa chỉsân vận động của đội kia là gì?======================== Tin nhắn từ AI =========================Lệnh gọi Công cụ: search (tìm kiếm)Đối số:query: Lịch thi đấu bóng bầu dục của đội Texas LonghornsTên: search (tìm kiếm)======================== Tin nhắn từ Công cụ ========================={...Kết quả: "Giải Bóng bầu dục NCAA Division I, Georgia, Ngày..."}======================== Tin nhắn từ AI =========================Đội Texas Longhorns đã đấu với đội Georgia Bulldogs vào tuần trước.Lệnh gọi Công cụ: places (địa điểm)Đối số:query: Sân vận động của đội Georgia Bulldogs======================== Tin nhắn từ Công cụ ========================={...Địa chỉ Sân vận động Sanford: 100 Sanford...}======================== Tin nhắn từ AI =========================Địa chỉ sân vận động của đội Georgia Bulldogs là 100 Sanford Dr, Athens, GA30602, Hoa Kỳ.
Đoạn mã 9: Kết quả trả về khi chạy tác nhân trong Đoạn mã 8
Mặc dù đây là một ví dụ tác nhân khá đơn giản, nhưng nó minh họa các thành phần nền tảng của tác nhân bao gồm Mô hình, Lớp điều hành và các Công cụ, tất cả phối hợp với nhau để đạt được một mục tiêu cụ thể.
Trong phần cuối cùng, chúng ta sẽ tìm hiểu cách các thành phần này kết hợp với nhau như thế nào trong các sản phẩm tác nhân trong Vertex AI và Generative Playbooks, đây là các sản phẩm phát triển bởi Google và có khả năng nhân rộng ở quy mô lớn.
Phát triển tác nhân với Google Vertex AI
Tài liệu này đã mô tả các thành phần và cấu trúc cốt lõi của một tác nhân, tuy nhiên, để xây dựng và phát triển tác nhân, cần có nền tảng phù hợp và quy trình bài bản. Đồng thời, nền tảng phát triển tác nhân cần đáp ứng nhiều yêu cầu khắt khe. Ví dụ, nền tảng cần tích hợp đa dạng yếu tố, đi kèm các công cụ dễ dùng, phương pháp đánh giá hiệu quả và cơ chế hỗ trợ nhà phát triển cải tiến liên tục.
Đồng thời, các yêu cầu về nền tảng sử dụng để phát triển tác nhân cũng rất cao, ví dụ các nền tảng cần có sự tích hợp của nhiều yếu tố, kèm theo các công cụ tương ứng có giao diện dễ sử dụng, các phương thức đánh giá hiệu quả, và cơ chế để giúp nhà phát triển cải tiến liên tục trong quá trình phát triển tác nhân.
Google Vertex AI là nền tảng lý tưởng để phát triển tác nhân. Nền tảng này cung cấp cho bạn khả năng quản lý toàn diện các thành phần và cấu trúc đã trình bày trong tài liệu.
Sử dụng giao diện ngôn ngữ tự nhiên thân thiện, nhà phát triển sẽ nhanh chóng xác định và thiết lập được các thành phần cốt lõi của tác nhân - các mục tiêu, hướng dẫn thực hiện nhiệm vụ, các công cụ, các tác nhân phụ được chuyên biệt hóa cho các nhiệm vụ con, các ví dụ mẫu - nhằm dễ dàng định hình hành vi hệ thống mong muốn. Ngoài ra, nền tảng này đi kèm với một bộ công cụ phát triển cho phép kiểm thử, đánh giá, đo lường hiệu suất của tác nhân, gỡ lỗi và cải thiện chất lượng tổng thể của các tác nhân đã phát triển. Điều này cho phép các nhà phát triển tập trung vào việc xây dựng và tinh chỉnh tác nhân của họ, mà không cần quan tâm nhiều đến các vấn đề phức tạp về cơ sở hạ tầng, triển khai và bảo trì - vốn được quản lý bởi chính nền tảng Google Vertex AI.
AI, bằng cách sử dụng nhiều tính năng khác nhau như Vertex Agent Builder, Tiện ích mở rộng (Vertex Extensions), Gọi Hàm Vertex (Vertex Function Calling) và Ngân hàng Ví dụ Vertex (Vertex Example Store), cùng một số tính năng khác. Kiến trúc này bao gồm nhiều thành phần cần thiết khác nhau, sẵn sàng cho quá trình thiết kế, phát triển và sản xuất tác nhân.
Tổng kết
Trong tài liệu này, chúng ta đã thảo luận về các nền tảng để xây dựng các tác nhân AI tạo sinh, thành phần cấu tạo của chúng và các phương pháp hiệu quả để triển khai chúng dưới dạng kiến trúc nhận thức. Dưới đây là những điểm tóm lược chính từ tài liệu này:
1. Tác nhân mở rộng khả năng của mô hình ngôn ngữ bằng cách tận dụng các công cụ để truy cập thông tin ở bên ngoài theo thời gian thực, đề xuất các hành động thực tế diễn ra trong thế giới thực, lập kế hoạch và đồng thời thực thi các nhiệm vụ phức tạp tương ứng một cách tự chủ. Tác nhân có thể tận dụng một hoặc nhiều mô hình ngôn ngữ để quyết định thời điểm và cách chuyển đổi giữa các trạng thái và sử dụng các công cụ bên ngoài để hoàn thành một hay nhiều nhiệm vụ phức tạp khác nhau, điều mà mà các mô hình khó hoặc không thể tự hoàn thành được.
2. Trung tâm hoạt động của một tác nhân là lớp điều hành, một kiến trúc nhận thức được cấu trúc hóa về khả năng lý luận, lập kế hoạch, ra quyết định và hướng dẫn các hành động của chính nó. Nhiều kỹ thuật lý luận khác nhau như ReAct, Chain-of-Thought và Tree-of-Thoughts cung cấp một khuôn mẫu cho lớp điều hành tiếp nhận thông tin, thực hiện lý luận nội bộ và tạo ra các quyết định hoặc các phản hồi sáng suốt.
3. Các công cụ, chẳng hạn như Tiện ích mở rộng (Extensions), Hàm (Functions) và Kho tri thức (Data Stores), đóng vai trò là chìa khóa để tác nhân kết nối với thế giới bên ngoài, cho phép chúng tương tác với các hệ thống bên ngoài và truy cập các kiến thức vượt ra ngoài dữ liệu mà chúng được đào tạo ban đầu.
Tiện ích mở rộng (Extensions) có vai trò cầu nối giữa tác nhân và API bên ngoài, cho phép thực hiện các lệnh gọi API và truy xuất thông tin từ bên ngoài theo thời gian thực.
Hàm (Functions) cung cấp cho nhà phát triển khả năng kiểm soát hệ thống chi tiết hơn thông qua việc phân chia công việc, cho phép tác nhân tạo ra các tham số Hàm (Function) có thể được thực thi ở phía máy khách (client-side).
Kho tri thức (Data Stores) cung cấp cho tác nhân quyền truy cập vào dữ liệu có cấu trúc hoặc phi cấu trúc từ bên ngoài, mở ra khả năng định hướng dữ liệu của ứng dụng (data-driven applications).
Có nhiều triển vọng về các tiến bộ của tác nhân trong tương lai và chúng ta chỉ mới bắt đầu khám phá ở phần bề mặt của những khả năng có thể xảy ra trong lĩnh vực xây dựng và phát triển tác nhân. Khi các công cụ trở nên tinh vi hơn, với khả năng lý luận được nâng cao, tác nhân sẽ được trao quyền để giải quyết các vấn đề ngày càng phức tạp hơn trong thực tế.
Hơn nữa, chiến lược tiếp cận về “xâu chuỗi tác nhân” tiếp tục giữ được động lực để tiến xa về phía trước. Với sự kết hợp các tác nhân chuyên biệt khác nhau - mỗi tác nhân vượt trội trong một lĩnh vực hoặc một nhiệm vụ cụ thể - chúng có thể tạo ra phương pháp tiếp cận “kết hợp các tác nhân chuyên gia”, có khả năng mang lại kết quả vượt trội trên nhiều ngành công nghiệp và lĩnh vực khác nhau.
Một điểm quan trọng cần lưu ý là việc xây dựng những kiến trúc tác nhân phức tạp đòi hỏi phương pháp tiếp cận có tính lặp đi lặp lại. Thử nghiệm và tinh chỉnh chính là chìa khóa để tìm ra giải pháp cho các yêu cầu kinh doanh cụ thể của từng tổ chức. Giống như con người, không có hai tác nhân nào được tạo ra giống nhau hoàn toàn và điều này xuất phát từ bản chất tạo sinh của các mô hình nền tảng chỉ đóng vai trò làm nền tảng cho kiến trúc của tác nhân. Tuy nhiên, bằng cách khai thác sức mạnh của từng thành phần nền tảng này, chúng ta có thể tạo ra những ứng dụng có tác động mạnh mẽ, mở rộng khả năng của mô hình ngôn ngữ và giúp các mô hình có những đóng góp nhiều giá trị hơn cho thế giới thực.
Danh sách Tác giả
Các tác giả:
Julia Wiesinger
Patrick Marlow
Vladimir Vuskovic
Reviewers and Contributors:
- Evan Huang
- Emily Xue
- Olcan Sercinoglu
- Sebastian Riedel
- Satinder Baveja
- Antonio Gulli
- Anant Nawalgaria
- Curators and Editors
- Antonio Gulli
- Anant Nawalgaria
- Grace Mollison
- Technical Writer
- Joey Haymaker
Designer
- Michael Lanning
Các tài liệu tham khảo
Shafran, I., Cao, Y. et al., 2022, ‘ReAct: Synergizing Reasoning and Acting in Language Models’. Available at: https://arxiv.org/abs/2210.03629
Wei, J., Wang, X. et al., 2023, ‘Chain-of-Thought Prompting Elicits Reasoning in Large Language Models’. Available at: https://arxiv.org/pdf/2201.11903.pdf.
Wang, X. et al., 2022, ‘Self-Consistency Improves Chain of Thought Reasoning in Language Models’. Available at: https://arxiv.org/abs/2203.11171.
Diao, S. et al., 2023, ‘Active Prompting with Chain-of-Thought for Large Language Models’. Available at: https://arxiv.org/pdf/2302.12246.pdf.
Zhang, H. et al., 2023, ‘Multimodal Chain-of-Thought Reasoning in Language Models’. Available at: https://arxiv.org/abs/2302.00923.
Yao, S. et al., 2023, ‘Tree of Thoughts: Deliberate Problem Solving with Large Language Models’. Available at: https://arxiv.org/abs/2305.10601.
Long, X., 2023, ‘Large Language Model Guided Tree-of-Thought’. Available at:
https://arxiv.org/abs/2305.08291.
Google. ‘Google Gemini Application’. Available at: http://gemini.google.com.
Swagger. ‘OpenAPI Specification’. Available at: https://swagger.io/specification/.
Xie, M., 2022, ‘How does in-context learning work? A framework for understanding the differences from traditional supervised learning’. Available at: https://ai.stanford.edu/blog/understanding-incontext/.
Google Research. ‘ScaNN (Scalable Nearest Neighbors)‘. Available at:
https://github.com/google-research/google-research/tree/master/scann.
- LangChain. ‘LangChain’. Available at: https://python.langchain.com/v0.2/docs/introduction/.
Share


Quick Links
Legal Stuff